Conception logicielle détaillée dans le cycle de vie du logiciel
Dans cette unité de cours, nous allons contextualiser le rôle du codage comme une seule activité du processus de développement logiciel et parcourir le cycle de vie du logiciel comme un chemin responsable vers un produit logiciel fiable.
Résumé de l'unité de cours
Le codage n’est qu’une seule activité dans le processus de développement logiciel. L’activité d’ingénierie commence plus tôt et se termine plus tard.
Le cycle de vie du développement logiciel (SDLC)
Jusqu’à présent, nous avons surtout réduit le développement logiciel au « codage ».
- Cependant, avec la phase de packaging de Maven, nous avons également vu comment le logiciel doit fonctionner en dehors de l’IDE (un livrable logiciel doit fonctionner en dehors de l’IDE)
- En fin de compte, nous construisons le logiciel non pour nous (les développeurs), mais pour les utilisateurs.
- Idéalement, ce que nous livrons à la fin de la journée répond parfaitement aux besoins de l’utilisateur.
Maîtriser Skyjo est relativement facile :
- Vous avez le règlement : Les exigences sont déjà plus ou moins gravées dans le marbre et assez claires.
- Vous avez des parties de la solution : Graphiques, interaction utilisateur, etc.
- Vous avez des interfaces qui guident votre implémentation.
Les novices en ingénierie logicielle confondent souvent l’ingénierie logicielle avec le simple codage. Mais la plupart des projets logiciels commencent beaucoup plus tôt et se terminent bien plus tard...
L’ingénierie logicielle concerne davantage les humains que le code.
Pour commencer, les utilisateurs ne savent pas toujours ce qu’ils veulent. En fait, la plupart du temps, ils ne le savent pas. C’est notre travail, en tant qu’ingénieurs logiciels, de donner un sens à leurs explications (souvent) confuses, chaotiques ou contradictoires, et néanmoins de construire quelque chose qui réponde à leurs exigences.
Définitions du cycle de vie logiciel
- La conception logicielle (détaillée) n’est qu’une seule activité lorsqu’il s’agit de développer un logiciel.
- Avant de plonger dans les décisions de conception pratiques, jetons un bref coup d’œil à la terminologie :
- Cycle de vie logiciel : phases par lesquelles un produit logiciel passe de l’idée initiale à sa mise hors service
- Processus logiciel : ensemble structuré d’activités et de pratiques suivies pour produire un logiciel (la méthodologie)
Ian Sommerville dit : Un processus logiciel est une séquence d’activités qui conduit à la production d’un produit logiciel. Il y a quatre activités fondamentales communes à tous les processus logiciels. Ces activités sont :
- Spécification logicielle, où les clients et les ingénieurs définissent le logiciel à produire et les contraintes sur son fonctionnement.
- Développement logiciel, où le logiciel est conçu et programmé.
- Validation logicielle, où le logiciel est vérifié pour s’assurer qu’il répond aux exigences du client.
- Évolution logicielle, où le logiciel est modifié pour refléter les exigences changeantes des clients et du marché.
Context
Dans cette conférence, nous nous concentrons principalement sur le deuxième point, c’est-à-dire que nous supposons que les exigences sont suffisamment spécifiées, et nous ne nous occupons pas de la validation ou de la maintenance. Selon le processus logiciel suivi, ces activités ne sont pas nécessairement entièrement séparées.
Modèles populaires
Les modèles les plus populaires, waterfall et agile, parcourent les activités définies par Sommerville. Par exemple, le modèle en cascade, ainsi que le modèle itératif, se basent sur au moins cinq phases :
1. analyse des exigences
2. conception conceptuelle
3. implémentation
4. tests
5. maintenance

Remarque : Le modèle en cascade semble strictement linéaire, mais des révisions occasionnelles des activités précédentes sont envisagées.
Analyse des exigences
- Idéalement, la première étape consiste toujours à obtenir une compréhension précise de ce qui est réellement souhaité.
- Malheureusement, cette étape est souvent soit complètement sautée, soit insuffisamment suivie.

L'analyse des exigences est essentielle
Commencer à coder sans une compréhension claire des exigences des utilisateurs est l’une des façons les plus efficaces de gaspiller des ressources et d’échouer dans un projet logiciel.
Cas d'utilisation textuels
Les cas d'utilisation textuels sont une description écrite des scénarios de succès. Ils décrivent dans quel ordre les acteurs (utilisateurs, composants) interagissent entre eux, pour aboutir progressivement à un résultat souhaité.
Les cas d'utilisation textuels contiennent (couramment) les sections suivantes :
- ID, Name, Primary actor
- Goal
- Preconditions
- Main flow
- Postconditions
- Alternate flow
- Exceptions
Il y en a généralement plusieurs
Typiquement, les systèmes sont trop complexes pour être décrits par un seul scénario de cas d'utilisation. Dans ce cas, les cas d'utilisation forment une hiérarchie allant des cas d'utilisation de haut niveau aux cas d'utilisation de niveau inférieur référencés, qui dans l’ensemble constituent une description précise de la façon dont le système est utilisé.
Exemple : Dispositif automatisé d’alimentation pour chat
Voici un problème courant pour les propriétaires de chats. Nos félins doivent être nourris tous les jours, mais parfois nous sommes absents (conférences, séjours dans une cabane dans les arbres, etc.). Malheureusement, nous ne pouvons pas simplement laisser un tas de nourriture pour chats, car nos animaux bien-aimés sont un peu en surpoids et ont tendance à manger plus qu’ils ne devraient.

Keksli. Mignon, mais ne connaît pas ses limites. S’il est laissé avec une montagne de nourriture pour chats, il mangera tout… et ensuite de mauvaises choses se produiront.
Voici une description d’un scénario de succès pour un système destiné à résoudre ce problème :
Use Case ID: ACFD-01
Use Case Name: Schedule Cat Feeding
Primary Actor: User
Goal:
To ensure the cat receives food automatically after a set countdown, even when the user is not home.
Preconditions:
- The A.C.F.D. is powered and operational.
- The Food Bay is empty or ready to be refilled.
- The User has access to the Control Panel.
Main Flow:
1. The User fills the Food Bay with food.
2. The User closes the Food Bay, ensuring the open status is “closed.”
3. The User sets a countdown time for release using the Control Panel.
4. The Control Panel sends the set time to the Display, which records the current time active value.
5. The Display updates the Control Panel with the countdown status as time progresses.
6. When the countdown reaches zero, the Control Panel triggers the Motor to drive the release mechanism.
7. The Motor changes the open status of the Food Bay to “open.”
8. The Cat, now able to access the food, empties the Food Bay by eating.
Postconditions:
- The Food Bay becomes empty.
- The open status remains "open" until manually reset by the User.
- The Cat’s hunger level is assumed satisfied.
Alternate Flow (Manual Abort):
- At any time before countdown completion, the User can read the Display and cancel or adjust the timer via the Control Panel.
Exceptions:
- If the Food Bay is not properly closed, the Control Panel does not allow the timer to start.
- If the Motor fails, the open command does not execute, and the User must intervene manually.
Quels concepts sont définis et comment se rapportent-ils au flux principal ?
- Les concepts sont : Utilisateur, Bac à nourriture, Panneau de contrôle, Affichage, Moteur, Chat
- Chaque élément du flux principal doit déclarer une interaction entre deux composants.
Modèle de domaine
- Les modèles de domaine sont extraits des cas d'utilisation, c’est-à-dire qu’ils représentent une visualisation des concepts listés dans la description textuelle du cas d'utilisation.
- Acteurs
- Composants
- Les modèles de domaine relient les concepts en fonction de leurs interactions, c’est-à-dire qu’aucune fonction n’est définie dans les concepts ; nous listons seulement « ce que chaque concept attend d’un autre » pour former des relations. Ces relations définissent :
- Préoccupation : ce qui est demandé
- Direction : qui demande, qui fournit
- Multiplicités : combien d’instances par instance
Exemple de relations
À partir d’un modèle de cas d’utilisation pour la rédaction d’examens, nous pourrions déduire que les professeurs créent des examens et que les étudiants les passent. En termes de concepts et de multiplicités, cela se traduit par :

Exemple de modèle de domaine : Dispositif automatisé d’alimentation pour chat
À partir de la description du cas d'utilisation ACFD précédente, nous pouvons extraire les concepts et relations suivants, pour construire un modèle de domaine :

Remarque : les losanges vides signifient une « agrégation », c’est-à-dire que le composant cible appartient au composant source et ne peut pas exister seul.
Peu de détails techniques jusqu’à présent
Gardez à l’esprit que le but d’un modèle de domaine est de capturer et comprendre les exigences du système. À ce stade, nous ne voulons pas inclure de détails techniques pertinents pour la solution, par exemple si l’utilisateur interagit avec le panneau de contrôle via des boutons, combien de boutons sont nécessaires, combien de segments sont nécessaires pour l’affichage, etc. Nous n’ajoutons pas de composants au-delà de ce qui est spécifié dans la description textuelle du cas d’utilisation.
Conception logicielle orientée objet
Une fois que les exigences sont formalisées, vous pouvez passer à la réflexion sur des solutions conceptuelles.
Vous met sur la voie de l’implémentation
Les diagrammes vous mettent sur la voie d’une implémentation réussie. Avec des diagrammes précis, l’implémentation devient une tâche directe. Il est plus rapide de prendre des décisions fondamentales (et de repérer les mauvaises décisions) sur papier, aux premières étapes, que d’implémenter toutes les classes pour ensuite réaliser que la solution est trop compliquée (ou ne peut pas fonctionner). La conception se fait sur papier, pas dans l’IDE.
- Bien que cette phase soit plus proche du code, cela ne signifie pas encore ouvrir un IDE et commencer à écrire votre logiciel.
- Avant de perdre du temps à implémenter du code dont vous pourriez ne pas avoir besoin, concentrez votre attention sur les décisions de conception, notamment :
- Structures de données
- Encodage de l’information (objets vs types primitifs)
- Hiérarchies de classes, interfaces et classes abstraites
- Stratégies de création d’objets
- Objets immuables vs objets mutables
- Idéalement, le résultat de cette phase vous fournit deux types de modèles pertinents pour l’implémentation :
- Diagrammes de classes : Quelles classes sont nécessaires, quelles méthodes elles offrent, comment elles se réfèrent les unes aux autres.
- Diagrammes de séquence : Comment les méthodes fonctionnent en interne pour fournir une fonctionnalité spécifique.
Les choix de conception sont par définition des décisions réfléchies
Les choix de conception sont basés sur des faits et du raisonnement. Les défauts évidents, par exemple documentation manquante, mauvais style de programmation, etc., ne sont pas des décisions de conception.
Capturer la conception structurelle avec des diagrammes de classes
Les diagrammes de classes définissent comment les concepts des exigences se traduisent en concepts de solution, quelle fonctionnalité est fournie par chaque composant de solution et comment ils se relient les uns aux autres, en termes de dépendances et de hiérarchies de classes. Plus en détail :
- Pour les classes :
- leurs champs
- leurs méthodes
- si elles sont statiques ou non
- si elles sont des classes, des interfaces ou abstraites
- Pour les relations :
- Héritage
- Dépendances
- Compositions
- Agrégations
Quelque chose manque-t-il pour l’implémentation ?
Oui ! Les diagrammes de classes ne nous disent rien sur le comportement, c’est-à-dire que nous savons quelles méthodes existent, mais nous ne savons pas comment elles fonctionnent.
Exemple : Zoo
- Nous devons implémenter un système imitant la voix des animaux pour un zoo, c’est-à-dire que nous voulons un petit programme qui produise le son d’un animal donné.
- Par exemple, si le système reçoit un
Tiger, il doit produireRrrrroarrr !. Nous ne savons pas combien d’animaux sont présents, ni lesquels exactement.
Un exemple de décision de conception dans ce cas est l’utilisation de vérifications de type versus le polymorphisme.
- Pour maintenir l’extensibilité, il pourrait être logique de stocker les animaux dans un
Set. - S’il y a des milliers d’animaux, nous pourrions modulariser le comportement, c’est-à-dire éviter d’avoir une séquence
if/else-ifunique. - Au lieu de vérifier manuellement les classes, nous pourrions utiliser le polymorphisme.
- Cependant, le polymorphisme implique également l’ajout de plus de classes, et si nos exigences précisent qu’il n’y aura que deux types d’animaux, éviter le polymorphisme pourrait être une décision de conception pertinente.
Option 1 : string map
La structure d’une solution basée sur une vérification de chaînes peut s’exprimer comme suit :
classDiagram
class Launcher {
}
class Zoo {
-animals: Map<string, string>
+addAnimal(type: string, sound: string)
+getSoundForType(type: string): string
}
Launcher "1" *--> "1" ZooOption 2 : Polymorphisme
La structure d’une solution polymorphe peut s’exprimer comme suit :
classDiagram
class Launcher {
}
class Zoo {
-animals: Map<string, Animal>
+addAnimal(name: string, a: Animal)
+getSoundForType(type: string): string
}
class Animal {
<<Interface>>
+makeSound(): string
}
class Tiger {
+makeSound(): string
}
class Lion {
+makeSound(): string
}
Animal <|-- Tiger
Animal <|-- Lion
Launcher "1" *--> "1" Zoo
Zoo "1" *-- "1..*" AnimalRemarque : Malheureusement, les multiplicités ont un support limité dans le format de diagramme utilisé ici.
Capturer la conception comportementale avec des diagrammes de séquence
Pour capturer véritablement toutes les décisions de conception nécessaires à une implémentation, nous devons également spécifier le fonctionnement des méthodes, c’est-à-dire « ce qui se passe à l’intérieur d’une méthode ».
- Cela se fait à l’aide de diagrammes de séquence, c’est-à-dire des définitions claires de qui appelle qui, et quelles appels potentiels sont requis à l’intérieur d’une méthode.
- Illustrons le format du diagramme en formalisant ce qui doit se passer dans la méthode
getSoundForTypepour l’une ou l’autre implémentation.
Option 1 : table de correspondance de chaînes
sequenceDiagram
participant L as Launcher
participant Z as Zoo
participant M as animals: Map<string, string>
L->>Z: getSoundForType("tiger")
activate Z
Z->>M: get("tiger")
activate M
M-->>Z: "Roar!"
deactivate M
Z-->>L: "Roar!"
deactivate Z- L’exécution des méthodes est illustrée par une boîte grise.
- Les appels sont des flèches noires (portant la fonction cible et les arguments)
- Les retours sont des flèches en pointillés (portant les valeurs de résultat)
Option 2 : Polymorphisme
sequenceDiagram
participant L as Launcher
participant Z as Zoo
participant M as animals: Map<string, Animal>
participant A as Animal (Tiger/Lion)
L->>Z: getSoundForType("tiger")
activate Z
Z->>M: get("tiger")
activate M
M-->>Z: Animal (Tiger)
deactivate M
Z->>A: makeSound()
activate A
A-->>Z: "Roar!"
deactivate A
Z-->>L: "Roar!"
deactivate ZCe deuxième diagramme révèle que la première solution est plus simple, puisqu’il n’est pas nécessaire d’utiliser le polymorphisme si nous stockons simplement tous les sons des animaux directement dans une table de correspondance.
Tests
Le logiciel peut être testé de plusieurs façons, mais on distingue généralement selon le périmètre (ou horizon), c’est-à-dire « quoi tester » :
| Horizon | Type de test | Exemple |
|---|---|---|
| Module isolé | Test unitaire | Appeler une classe Java avec l’entrée x retourne y. |
| Interaction de plusieurs modules | Tests d’intégration | Le système envoie un courriel à alert@uqam.ca lorsqu’une condition critique survient. |
| Interaction de tout le système | Test système | Cliquer sur accept finalise la réservation de vol et génère le PDF de la carte d’embarquement. |
| Aspect non fonctionnel | Test d’acceptation | Le système réagit suffisamment rapidement pour un usage productif. |
En général
En général, les tests deviennent plus difficiles (et coûteux) à mesure que l’horizon s’élargit. Par exemple, les tests unitaires ne sont pas coûteux comparés à l’embauche d’utilisateurs de test qui tentent d’interagir avec votre système.
Tests et phases antérieures
Même sans implémentation, les premières phases du cycle de vie du développement logiciel préparent le terrain pour les tests. L’analyse des exigences et l’élaboration de la conception définissent :
- Quelles méthodes sont nécessaires.
- Quel comportement est attendu.
À partir de ces deux éléments, nous pouvons en fait définir des tests unitaires avant d’avoir une implémentation. Cette pratique est également appelée « développement piloté par les tests ».
Exemple
Pour un vérificateur de nombres premiers, nous pouvons créer des tests unitaires afin de vérifier les sorties pour des entrées spécifiques :
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertTrue;
import org.junit.Test;
public class PrimeCheckerTest {
private final PrimeChecker checker = new PrimeChecker();
/**
* Tests if the number 23 is correctly identified as a prime number.
*/
@Test
public void testIsPrime23() {
assertTrue(checker.isPrime(23));
}
}
Attention au contournement des tests
Réussir les tests n’est pas une garantie de correction. Si vous ne faites pas confiance à un développeur, ne fournissez pas tous les tests à l’avance – il pourrait manipuler les résultats de vos tests.
Maintenance
Bien que la maintenance ne soit pas traitée en profondeur dans ce cours, gardez à l’esprit que le cycle de vie du logiciel ne se termine pas à la livraison d’un logiciel au client.
Même si le logiciel est parfait au moment de la livraison, le travail n’est pas terminé, car l’environnement évolue constamment :
- Le JDK peut changer, une méthode peut être dépréciée ou jugée non sécurisée.
- Le matériel peut changer, de nouveaux processeurs incompatibles peuvent remplacer les actuels.
- Et le pire… les exigences peuvent changer (la migration d’un ancien logiciel coûte extrêmement cher).
pie title Cost illustration of SDLC phases
"Requirement" : 3
"Design" : 8
"Implementation" : 7
"Testing" : 15
"Maintenance" : 67Qu’en est-il des architectures ?
Dans le déroulé du cours, nous sommes passés directement de l’analyse des exigences à la conception OO. Souvent, la conception implique également des macro-structures, également appelées choix « d’architecture logicielle ».
Pour clarifier la distinction :
- La conception OO concerne les classes individuelles, leurs fonctions, leurs relations.
- L’architecture concerne les macro-préoccupations :
- Quels composants principaux sont présents dans un système (ex. packages)
- Comment l’information circule entre ces composants, y a-t-il des restrictions
Modèle, Vue, Contrôleur
Un exemple vu en classe est le MVC. Le MVC est un motif (ou style) architectural, divisant le logiciel en trois unités conceptuelles :
- Modèle : pour représenter l’état du système
- Contrôleur : pour transférer l’état du système de manière cohérente, afin que le modèle ne soit jamais corrompu / dans un état incohérent.
- Vue : pour représenter l’état du modèle et traiter les interactions utilisateur, en les mappant sur des actions du contrôleur
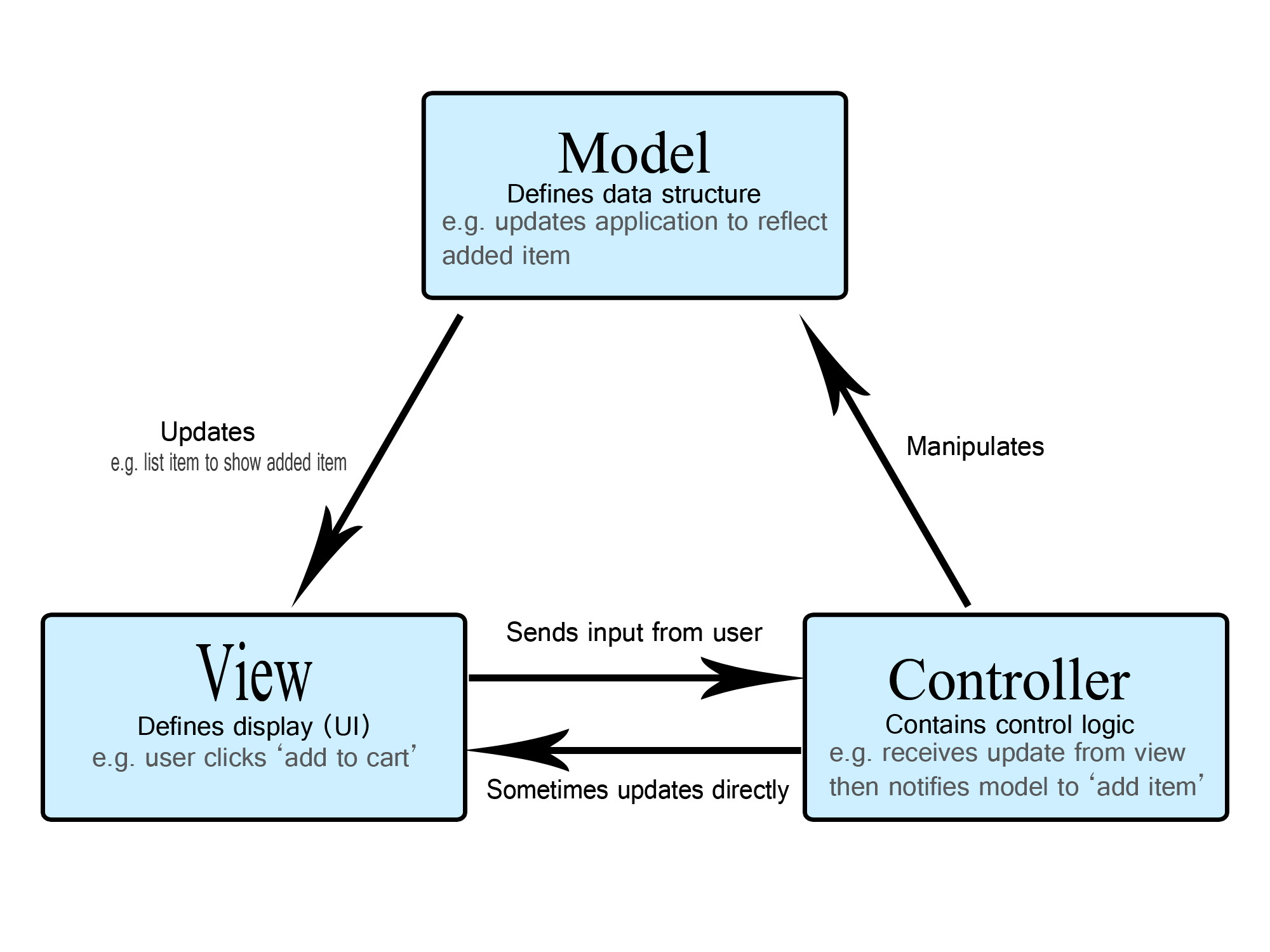
L’intérêt principal du MVC est de fournir une protection pour les applications. Intuitivement, vous pourriez être tenté d’implémenter n’importe quel système uniquement avec une interface utilisateur et un modèle. C’est possible, mais alors vous n’avez aucune protection d’intégrité :
- N’importe qui peut tout modifier.
- Les erreurs de programmation dans l’interface utilisateur risquent de corrompre l’état de votre application. Pensez simplement à une application bancaire, où tous les clients ont un accès complet à la base de données et sont censés gérer correctement la monnaie dans votre modèle...
DIVERS
Pour conclure la conférence, voici quelques considérations philosophiques pour l’ingénierie logicielle responsable.
Sur le rôle des exigences
L’ingénierie consiste à satisfaire les exigences :
- Le produit doit répondre aux exigences (et non l’inverse).
- Si le produit ne répond pas aux exigences, les ingénieurs ont échoué dans leur mission.
Si vous ne connaissez qu’un marteau, tout ressemble à un clou.
Malheureusement, les ingénieurs inexpérimentés ont souvent tendance à penser « solution d’abord », plutôt que « problème d’abord » :
Si le seul outil que vous savez utiliser est un marteau, tout vous paraît être un clou.
Pourquoi l’ingénierie n’est pas triviale :
- Vous devez comprendre les exigences :
- Lire et écouter attentivement.
- Être empathique et anticiper les besoins.
- Vous devez être capable de sélectionner l’outil le plus approprié :
- Connaître plus d’un outil.
- Comprendre dans quels contextes chaque outil s’adapte le mieux.
- Comparer le contexte du problème aux outils disponibles.
- Gérer les compromis.
- Savoir utiliser efficacement l’outil choisi.
L’ingénierie consiste à gérer des compromis
Il existe rarement une solution parfaite unique. L’ingénierie consiste à comprendre et équilibrer les risques, tout en gardant l’attention sur ce qui compte le plus. Les contraintes non techniques telles que le temps et le budget jouent souvent un rôle significatif également.
Mauvaise ingénierie
L’ingénierie consiste à assumer la responsabilité d’un produit logiciel :
- S’il n’y a pas besoin de responsabilité, alors il n’y a pas besoin d’ingénieur.
- En tant qu’ingénieur logiciel, la valeur que vous apportez à une entreprise correspond à la responsabilité que vous prenez pour votre code.
Personne, vraiment personne n’a besoin d’un ingénieur qui :
- Choisit une solution sans réfléchir aux alternatives.
- Copie-colle du code (une solution) sans savoir comment cela fonctionne.
- Utilise un LLM pour générer du code qu’il ne comprend pas, et appuie simplement sur « exécuter » jusqu’à ce que ça « marche » apparemment.
… ce n’est pas de l’ingénierie, c’est de la programmation par essais et erreurs.
Cependant, il est acceptable d’utiliser des solutions modernes, si vous pouvez en assumer la responsabilité :
- Il est acceptable d’utiliser des outils externes, IDE, outils de modélisation, etc.
- Il est acceptable de chercher des exemples de code en ligne.
- Il est acceptable de demander à un LLM. (note secondaire : les développeurs seniors qui utilisent des LLMs tendent à voir une baisse de performance.)
- Il n’est pas acceptable de coller du code que vous ne comprenez pas à 100 %. Vous êtes responsable de chaque ligne de code que vous utilisez.
Ne comptez pas sur l’IA générative pour des décisions critiques
L’IA générative, en particulier les LLMs, opère sur des modèles linguistiques qui complètent le texte fourni avec ce qui est statistiquement le plus probable.
Pour paraphraser ce que cela signifie :
- Les outils IA n’ont aucune compréhension cognitive du domaine du problème. Ils enveloppent simplement le contexte existant avec des complétions plausibles – pour les humains, nous appelons cela "bullshitting".
- L’hallucination en tant que concept n’est pas nouvelle, seul le terme l’est, comme un nouvel euphémisme pour ce que nous appelions auparavant un bug logiciel : un défaut inhérent qui rend un logiciel non fiable.

Littérature
Inspiration et lectures complémentaires pour les esprits curieux :